

Funkce UNNEST vs. EXPLODE
Vertica poskytuje dvě funkce, UNNEST a EXPLODE pro rozšíření polí do jednoho nebo více řádků. Tyto funkce nabízejí stejnou funkčnost s jemnými rozdíly v syntaxi a výstupu. Pojďme to pochopit na jednoduchém příkladu. CREATE TABLE orders ( orderkey VARCHAR, custkey INT, prodkey ARRAY[VARCHAR], orderprices ARRAY [DECIMAL (12,2)], email_addrs [...]

Jak filtrovat vzorec chování v časové řadě
Vzorce chování v časových řadách jsou něco, co mnoho analytiků chce najít v časových řadách. Analytik klikacího proudu chce najít sérii kliknutí, ke kterým došlo mezi příchodem na web, procházením jednoho nebo více článků na webu a konečným naplněním košíku a odhlášením. finanční analytik chce v křivkách hodnot akcií najít tvary V, [...]
Vyrovnávání zátěže na elastických clusterech Kubernetes
Vaše dlouhotrvající relace mohou selhat poté, co jste nasadili Vertica na Elastic Kubernetes Cluster (EKS) s Load Balancer jako typem služby. dbadmin@v-sc-0:/$ /opt/vertica/bin/vsql -h internal-acc1a79a37984458b9930acd01cba3f5-782667786.us-east-1.elb.amazonaws.com -c "select sleep(70);" server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. connection to server was [...]

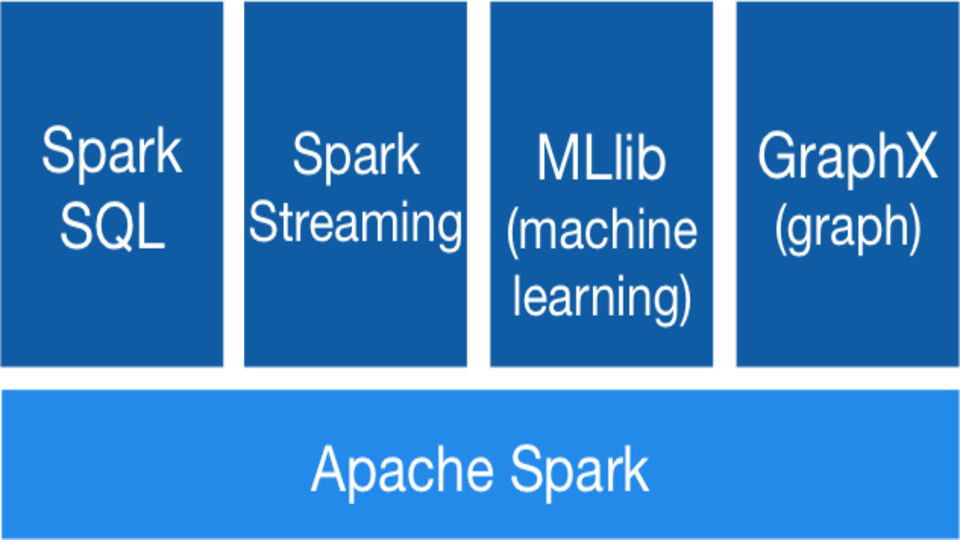
Spark na cluster chytře
Apache Spark je open-source distribuovaný univerzální framework určený k provádění výpočtů na úrovni clusteru. Největší výhodou je právě možnost paralelizace na vysoké úrovni a dostupnosti v tzv. módu „High Availability“ (HA), neboli vysoká dostupnost. Díky těmto vlastnostem je Apache Spark naprosto ideální pro nasazení v prostředí pro zpracování velkého množství dat [...]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
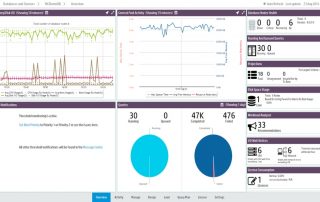
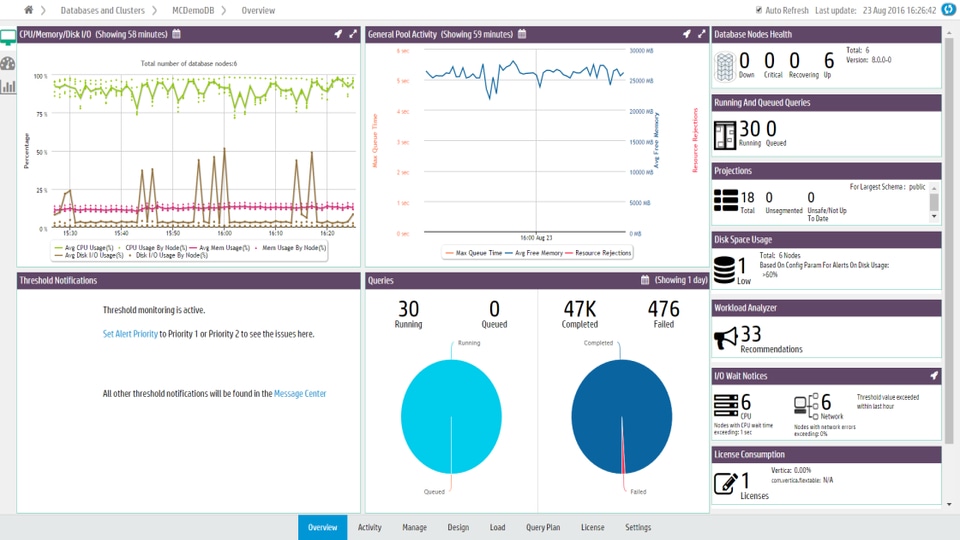
Vertica: databáze s velkým výkonem
Vertica V dnešní době, kdy se hromadí spousty dat, které je neustále nutné archivovat pro různé účely, se jeví „běžné“ databázové systémy jako neefektivní a velice pomalé. Terabajt je dnešní měrná jednotka pro databázové systémy. Spousty a spousty záznamů o transakcích, událostech, měřených údajích a dalších, se nemusí pouze [...]