

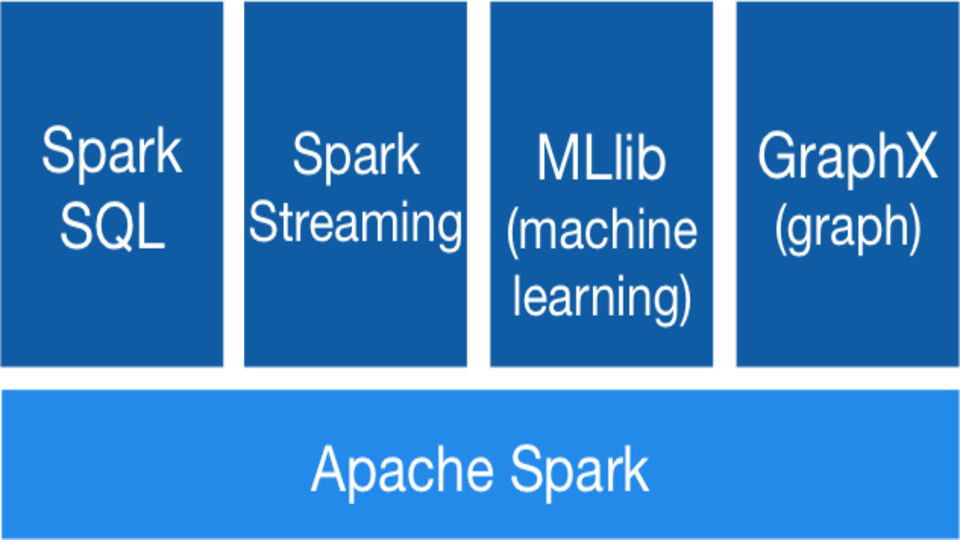
Spark na cluster chytře
Apache Spark je open-source distribuovaný univerzální framework určený k provádění výpočtů na úrovni clusteru. Největší výhodou je právě možnost paralelizace na vysoké úrovni a dostupnosti v tzv. módu „High Availability“ (HA), neboli vysoká dostupnost. Díky těmto vlastnostem je Apache Spark naprosto ideální pro nasazení v prostředí pro zpracování velkého množství dat [...]
Vertica: databáze s velkým výkonem
Vertica V dnešní době, kdy se hromadí spousty dat, které je neustále nutné archivovat pro různé účely, se jeví „běžné“ databázové systémy jako neefektivní a velice pomalé. Terabajt je dnešní měrná jednotka pro databázové systémy. Spousty a spousty záznamů o transakcích, událostech, měřených údajích a dalších, se nemusí pouze [...]
{kind=link}
{kind=link}
{kind=link}
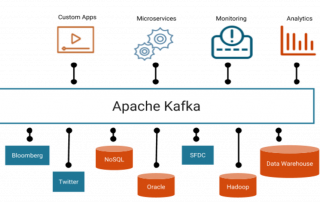
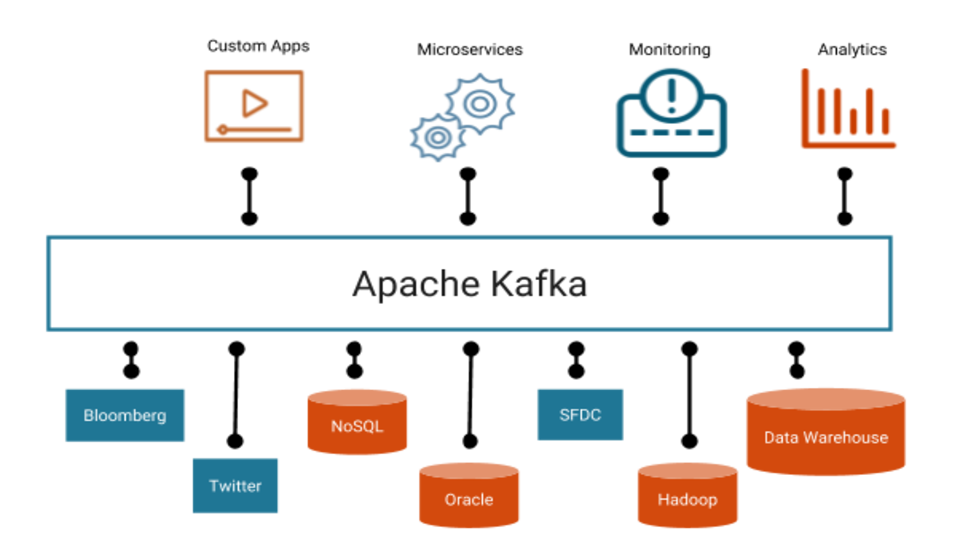
Představujeme Apache Kafka pro zpracování datových toků v reálném čase
Apache Kafka je open-source distribuovaná streamovací platforma s vysokou propustností a nízkou latencí pro zpracování datových toků v reálném čase. Jako streamovací platforma nabízí Kafka tyto schopnosti: Publikování a přihlášení se k odběru streamů záznamů, podobných frontám zpráv. Trvalé ukládání stream záznamů způsobem odolným proti chybám. [...]