

{kind=link}
Spark na cluster chytře
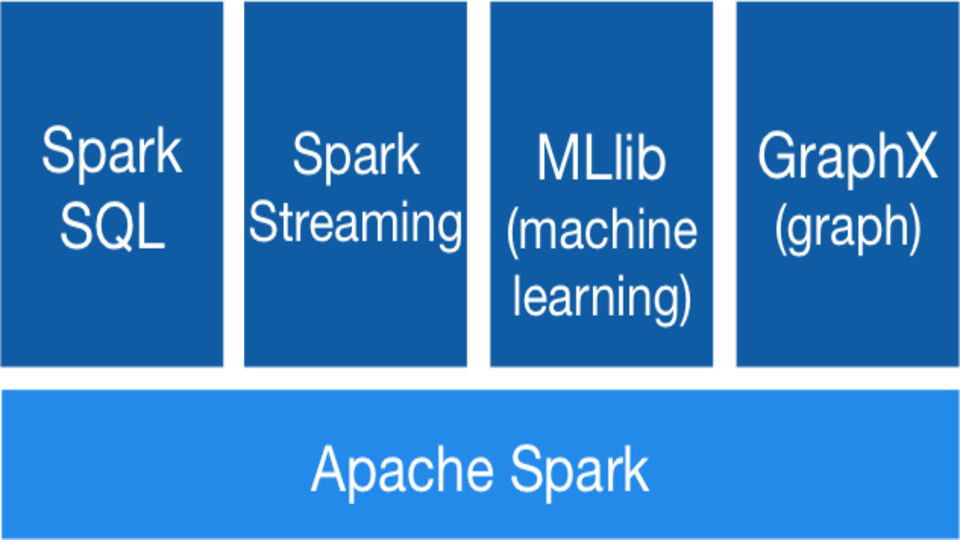
Apache Spark je open-source distribuovaný univerzální framework určený k provádění výpočtů na úrovni clusteru. Největší výhodou je právě možnost paralelizace na vysoké úrovni a dostupnosti v tzv. módu „High Availability“ (HA), neboli vysoká dostupnost. Díky těmto vlastnostem je Apache Spark naprosto ideální pro nasazení v prostředí pro zpracování velkého množství dat [...]